아래 포스팅에서 멀티 쓰레드 환경에서의 작업을 위한 쓰레드 풀을 생성하기 위한 다양한 인터페이스에 대해서 작성하였습니다.
https://silver-programmer.tistory.com/entry/Executor-ExecutorService%EC%99%80-ThreadPoolExecutor
[Multi-Thread] Executor, ExecutorService와 ThreadPoolExecutor
자바에서는 다중 쓰레드 환경에서 작업을 비동기적으로 실행하기 위한 다양한 인터페이스와 클래스를 제공하고 있습니다. 대표적으로 Executor 인터페이스가 있고, Executor를 확장한 인터페이스인
silver-programmer.tistory.com
여기에서 ThreadPoolExecutor에 대해서도 간략하게 설명을 하였는데, ThreadPoolExecutor는 ExecutorService 인터페이스를 구현하는 구현체로, 쓰레드 풀의 크기나 작업 대기 큐 등 다양한 설정들을 설정함으로써 조금 더 유연하게 쓰레드 풀을 생성할 수 있었습니다.
int corePoolSize = 5;
int maxPoolSize = 10;
long keepAliveTime = 1000;
BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>();
ExecutorService customThreadPool = new ThreadPoolExecutor(
corePoolSize,
maxPoolSize,
keepAliveTime,
TimeUnit.MILLISECONDS,
workQueue
);
이번 포스팅에서는 ThreadPoolExecutor에 대해서 더 자세하게 설명하였습니다. ThreadPoolExecutor에서 제공하는 다양한 설정값들을 어떻게 설정하고, 각 설정값들을 지정할 때 어떤 부분을 주의해야 하는지 등에 대해서 작성하였습니다.
ThreadPoolExecutor 형태
ThreadPoolExecutor의 생성자는 여러 매개변수를 받아 쓰레드 풀을 초기화합니다. 주요 생성자 형태는 아래와 같습니다.
ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
ThreadPoolExecutor의 주요 설정값들(생성자 매개변수)과 그 역할에 대해 간략히 작성해 보았습니다.
ThreadPoolExecutor 설정값
- corePoolSize (int):
- 항상 유지할 최소 쓰레드 수입니다. 작업 큐에 작업이 쌓이면 이 수 이상의 쓰레드가 존재할 수 있습니다.
- maximumPoolSize (int):
- 최대 쓰레드 수입니다. 작업 큐에 작업이 계속해서 쌓이면, 최대 쓰레드 수까지 쓰레드 개수 증가할 수 있습니다.
- keepAliveTime (long):
- idle 상태의 쓰레드가 유지될 최대 시간입니다. 작업이 없는 상태에서 keepAliveTime 동안 대기하다가, 이 시간이 경과하면 corePoolSize 이하로 쓰레드를 종료합니다.
- unit (TimeUnit):
- keepAliveTime의 시간 단위입니다.
- workQueue (BlockingQueue<Runnable>):
- 작업을 보관하는 큐로, 쓰레드 풀에 제출된 작업이 큐에 쌓입니다. 큐 구현체로는 LinkedBlockingQueue, ArrayBlockingQueue, SynchronousQueue 등이 사용될 수 있습니다. (아래는 공식문서에서 가져온 각 Blocking 큐 구현체에 대한 설명입니다.)
-
더보기Any BlockingQueue may be used to transfer and hold submitted tasks. The use of this queue interacts with pool sizing:
- If fewer than corePoolSize threads are running, the Executor always prefers adding a new thread rather than queuing.
- If corePoolSize or more threads are running, the Executor always prefers queuing a request rather than adding a new thread.
- If a request cannot be queued, a new thread is created unless this would exceed maximumPoolSize, in which case, the task will be rejected.
- Direct handoffs. A good default choice for a work queue is a SynchronousQueue that hands off tasks to threads without otherwise holding them. Here, an attempt to queue a task will fail if no threads are immediately available to run it, so a new thread will be constructed. This policy avoids lockups when handling sets of requests that might have internal dependencies. Direct handoffs generally require unbounded maximumPoolSizes to avoid rejection of new submitted tasks. This in turn admits the possibility of unbounded thread growth when commands continue to arrive on average faster than they can be processed.
- Unbounded queues. Using an unbounded queue (for example a LinkedBlockingQueue without a predefined capacity) will cause new tasks to wait in the queue when all corePoolSize threads are busy. Thus, no more than corePoolSize threads will ever be created. (And the value of the maximumPoolSize therefore doesn't have any effect.) This may be appropriate when each task is completely independent of others, so tasks cannot affect each others execution; for example, in a web page server. While this style of queuing can be useful in smoothing out transient bursts of requests, it admits the possibility of unbounded work queue growth when commands continue to arrive on average faster than they can be processed.
- Bounded queues. A bounded queue (for example, an ArrayBlockingQueue) helps prevent resource exhaustion when used with finite maximumPoolSizes, but can be more difficult to tune and control. Queue sizes and maximum pool sizes may be traded off for each other: Using large queues and small pools minimizes CPU usage, OS resources, and context-switching overhead, but can lead to artificially low throughput. If tasks frequently block (for example if they are I/O bound), a system may be able to schedule time for more threads than you otherwise allow. Use of small queues generally requires larger pool sizes, which keeps CPUs busier but may encounter unacceptable scheduling overhead, which also decreases throughput.
-
- 작업을 보관하는 큐로, 쓰레드 풀에 제출된 작업이 큐에 쌓입니다. 큐 구현체로는 LinkedBlockingQueue, ArrayBlockingQueue, SynchronousQueue 등이 사용될 수 있습니다. (아래는 공식문서에서 가져온 각 Blocking 큐 구현체에 대한 설명입니다.)
- threadFactory (ThreadFactory):
- 새로운 쓰레드를 생성하는데 사용되는 팩토리입니다. 기본값으로는 Executors.defaultThreadFactory()가 사용됩니다.
- handler (RejectedExecutionHandler):
- 작업이 큐에 추가되지 못하는 경우(일반적으로 최대 쓰레드 수 및 큐 용량이 모두 가득 찬 경우) 어떻게 처리할지를 결정합니다. 기본값으로는 AbortPolicy가 사용되며, 다른 옵션으로 CallerRunsPolicy, DiscardPolicy, DiscardOldestPolicy가 있습니다.
- 아래는 공식문서에서 가져온 RejectedTasks에 대한 policy에 대한 설명입니다.
-
더보기Rejected tasksNew tasks submitted in method execute(Runnable) will be rejected when the Executor has been shut down, and also when the Executor uses finite bounds for both maximum threads and work queue capacity, and is saturated. In either case, the execute method invokes the RejectedExecutionHandler.rejectedExecution(Runnable, ThreadPoolExecutor) method of its RejectedExecutionHandler. Four predefined handler policies are provided:
- In the default ThreadPoolExecutor.AbortPolicy, the handler throws a runtime RejectedExecutionException upon rejection.
- In ThreadPoolExecutor.CallerRunsPolicy, the thread that invokes execute itself runs the task. This provides a simple feedback control mechanism that will slow down the rate that new tasks are submitted.
- In ThreadPoolExecutor.DiscardPolicy, a task that cannot be executed is simply dropped.
- In ThreadPoolExecutor.DiscardOldestPolicy, if the executor is not shut down, the task at the head of the work queue is dropped, and then execution is retried (which can fail again, causing this to be repeated.)
-
- allowCoreThreadTimeOut (boolean):
- true로 설정하면 corePoolSize의 스레드도 keepAliveTime 이후에 종료될 수 있습니다.
이러한 설정값들을 조절하여 ThreadPoolExecutor의 동작을 조절할 수 있습니다.
하이라이트 되어 있는 corePoolSize, maximumPoolSize, workQueue들이 어떻게 동작하는지 제대로 알고 잘 설정하는 것이 멀티 쓰레드를 통한 비동기 작업을 구현할 때의 핵심인 것 같습니다. 각 설정값들이 어떻게 상호작용해서 쓰레드 풀을 관리하는지 자세히 살펴보겠습니다.
corePoolSize를 3, maximumPoolSize를 10, workQueue 사이즈를 10으로 설정하고, 수행해야 하는 작업이 10개라고 해 보겠습니다.
쓰레드들이 작업을 수행하는 단계는 아래와 같습니다.
- 먼저 corePoolSize만큼 쓰레드들을 쓰레드 풀에 생성합니다. (쓰레드 개수: 3)
- 작업의 개수(10)가 corePoolSize(3) 보다 많습니다. 3개의 작업은 쓰레드 풀에 생성된 각 쓰레드에 할당되어 수행이 되지만, 나머지 7개의 작업들은 작업 큐에 대기하게 됩니다.
- 그 후, 쓰레드 풀에 생성된 각 쓰레드들이 자신들에게 할당된 작업들을 완료하면 작업 큐에 대기하고 있는 작업들을 하나씩 꺼내와 수행하게 됩니다.
그렇다면, maximumPoolSize는 언제 사용되는 것일까요? 만약, 작업 큐에 대기해야 하는 작업들이 작업 큐의 사이즈를 넘어가게 되면, 최대 maximumPoolSize까지 쓰레드를 생성하여 작업 큐에 대기하지 못하는 작업들을 수행하도록 합니다.
이를 확인하기 위해 이번에는 corePoolSize를 3, maximumPoolSize를 10, workQueue 사이즈를 5로 설정하고, 수행해야 하는 작업이 10개라고 해 보겠습니다.
public class ThreadTest {
void test() {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
3, // corePoolSize
10, // maximumPoolSize
100, // keepAliveTime
TimeUnit.MICROSECONDS, // TimeUnit
new LinkedBlockingQueue<>(5)); // workQueue
for (int i = 0; i < 10; ++i) { // 작업 개수 10개
System.out.println("Active Thread: " + threadPoolExecutor.getActiveCount());
System.out.println("Queue Size: " + threadPoolExecutor.getQueue().size());
System.out.println("====================================================");
final int taskId = i;
threadPoolExecutor.submit(() -> {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
});
}
}
}
위와 같이 작성하여 각 단계에서 생성된 쓰레드 개수와 작업 큐에 대기 중인 작업 개수를 출력해 보았습니다. 아래 결과에 단계별로 어떻게 쓰레드가 생성되고 작업 큐에 작업들이 쌓이게 되는지 설명하였습니다.

결국, maximumPoolSize는 작업 큐의 공간이 다 차게 될 경우에 쓰레드 생성에 사용된다는 것을 확인할 수 있었습니다. 이렇게 내부 동작 방식을 파악하여, 작업 큐의 사이즈를 적절하게 설정해야 예상치 못한 메모리 누수가 발생하지 않도록 설정값을 잘 설정해야 한다는 것을 배울 수 있었습니다. (저는 처음에 maximumPoolSize 만큼 쓰레드가 증가하고, 그 후 작업 큐에 작업들이 쌓인다고 생각했습니다 ㅎㅎ.. 이렇게 생각해서 만약 작업 큐의 사이즈를 크게 잡는다면, maximumPoolSize 만큼 쓰레드는 생성되지 못하고 작업들이 계속 큐에 남아있게 되어 메모리가 과도하게 사용될 위험이 있겠죠? )
만약, 작업 큐에 빈 공간이 없고, maximumPoolSize 만큼 쓰레드들이 생성되었는데도 처리가 필요한 작업들이 계속 생성된다면 어떻게 될까요? 아래 코드를 통해 확인해 보겠습니다.
corePoolSize를 3, maximumPoolSize를 5, workQueue 사이즈를 3으로 설정하고, 수행해야 하는 작업이 10개라고 해 보겠습니다. (maximumPoolSize + workQueueSize < 10)
public class ThreadTest {
void test() {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
3, // corePoolSize
5, // maximumPoolSize
100, // keepAliveTime
TimeUnit.MICROSECONDS, // TimeUnit
new LinkedBlockingQueue<>(3)); // workQueue
for (int i = 0; i < 10; ++i) {
System.out.println("Active Thread: " + threadPoolExecutor.getActiveCount());
System.out.println("Queue Size: " + threadPoolExecutor.getQueue().size());
System.out.println("====================================================");
final int taskId = i;
threadPoolExecutor.submit(() -> {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
});
}
System.out.println("Active Thread: " + threadPoolExecutor.getActiveCount());
System.out.println("Queue Size: " + threadPoolExecutor.getQueue().size());
System.out.println("====================================================");
}
}
결과는 아래와 같이 최대 쓰레드 풀 크기만큼 쓰레드가 생성되고 RejectedExecutionException 에러가 발생합니다.
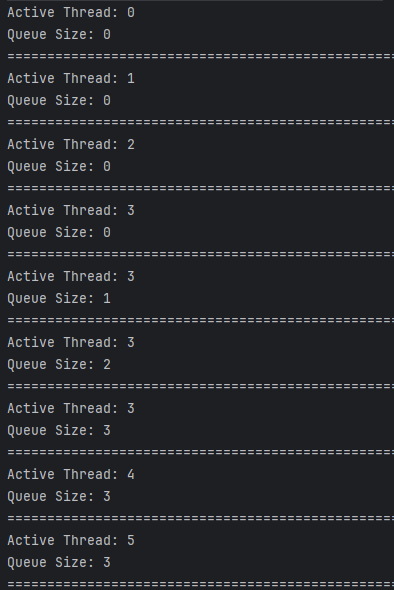

해당 exception을 해결하는 방법은 쓰레드 풀 크기나 작업 큐를 조정하거나, 아래와 같이 직접 RejectedExecutionHandler를 사용하여 에러를 직접 핸들링할 수 있습니다.
public class MyRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 거부 처리 로직을 여기에 구현
System.err.println("작업이 거부되었습니다: " + r.toString());
}
}
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
3,
5,
100,
TimeUnit.MICROSECONDS,
new LinkedBlockingQueue<>(3),
new MyRejectedExecutionHandler()); // handler 추가
이렇게 설정하고 다시 코드를 실행하면 exception을 발생시키지 않고 제대로 핸들링하는 것을 확인할 수 있습니다.
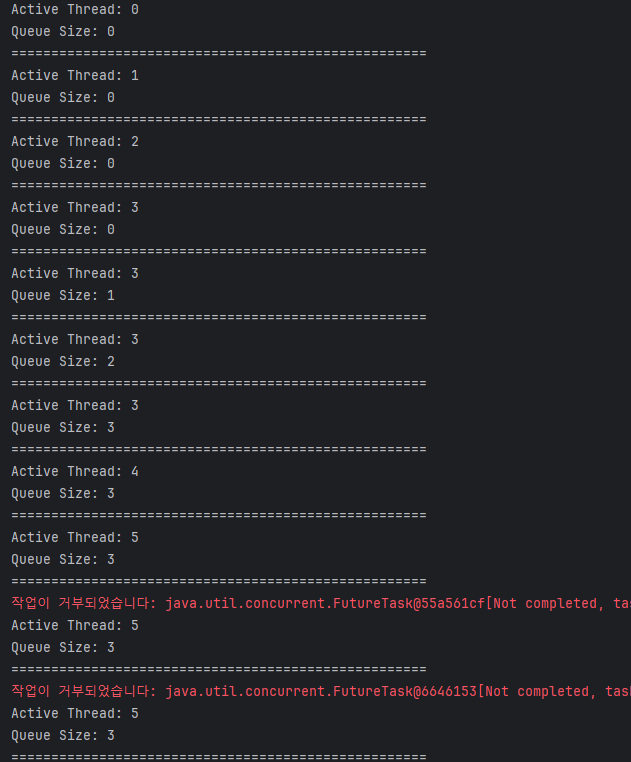
이렇게 ThreadPoolExecutor에 대해서 알아보았습니다. 회사에서 멀티 쓰레드로 비동기 작업을 구현해야 했었는데 해당 동작 방식을 제대로 알지 못하고 사용하였다면 메모리 및 성능 측면에서 문제가 발생할 수도 있었겠다는 것을 배울 수 있었습니다.
[참고자료]
https://leeyh0216.github.io/posts/truth_of_threadpoolexecutor/
ThreadPoolExecutor에 대한 오해와 진실
ThreadPoolExecutor에 대한 오해와 진실
leeyh0216.github.io
'Java' 카테고리의 다른 글
| [DB] 커넥션 풀이란? (Connection pool) (0) | 2024.08.03 |
|---|---|
| [Multi-Thread] execute() vs submit() (0) | 2024.01.28 |
| [Multi-Thread] Executor, ExecutorService와 ThreadPoolExecutor (0) | 2024.01.27 |
| [Multi-Thread] 쓰레드 결과 기다리기 (Future, submit(), get()) (1) | 2024.01.26 |
| 자바의 직렬화 (Serialization) (0) | 2023.11.10 |


