최근에 회사에서 멀티 쓰레드로 병렬 처리를 하는 코드를 구현해야 했습니다. Java에서 제공하는 ExecutorService를 이용하여 Thread Pool (쓰레드 풀)을 생성하고, 각 쓰레드들에게 작업을 던진 후, 각 쓰레드의 작업 결과값을 받아서 후처리를 해주어야 하는 코드를 작성해야 했습니다. 그 과정에서 여러 가지 배운 점이 있어 정리하고자 포스팅을 작성하였습니다.
처음에는 아래와 같이 Runnable과 Executor 클래스의 execute()을 이용해 코드를 작성하였습니다.
(참고로, ExecutorService는 Executor를 상속하기 때문에 타입이 ExecutorService여도 execute() 메서드 사용이 가능합니다.)
public class ThreadTest {
void runnableTest() {
ExecutorService executor = Executors.newFixedThreadPool(3); // 쓰레드 3개 생성
List<Integer> data = new ArrayList<>();
List<Integer> odds = new CopyOnWriteArrayList<>(); // thread-safe list
for (int i = 0; i < 20; ++i) data.add(i);
data.forEach(value -> {
Runnable runnable = () -> {
System.out.printf("Thread: %s, Data: %d\n", Thread.currentThread().getName(), value);
if (value % 2 == 1) odds.add(value); // 홀수 저장
try {
Thread.sleep(1000); // 1초 sleep
} catch (InterruptedException e) {
e.printStackTrace();
}
};
executor.execute(runnable);
});
System.out.println("===============================");
System.out.println("size: "+odds.size());
odds.forEach(System.out::println);
executor.shutdown();
}
}
위 코드에서 기대하는 바는, ExecutorService에서 만든 3개의 쓰레드가 협력하여 20개의 데이터를 출력 후, odds 배열에 홀수인 데이터만 저장하도록 하여서, 마지막에는 odds 배열에서 홀수가 출력되는 것입니다. 하지만, 위와 같이 작성하면 결과는 아래와 같이 엉뚱하게 나옵니다.
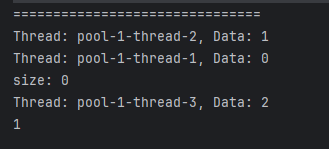
이는, 각 개별 쓰레드가 처리한 결과를 기다리지 않고, 메인 함수(runnableTest())를 그대로 진행하기 때문입니다.
물론 위 코드는 예시 코드입니다. 저는 처음에 동작 과정이 어떻게 되는지 잘 몰랐고 이렇게 예시 코드와 비슷한 방식으로 코드를 구현하였는데, 회사 선배님께서 이렇게 작성하면 각 개별 쓰레드의 결과를 기다리지 않고 메인 쓰레드가 종료되어서 의도한 결과가 나오지 않는다고 해주셨습니다.
즉, ExecutorService의 executor.execute()을 통해, 각 작업들을 쓰레드 풀의 쓰레드들에게 일단 던지고, 메인 쓰레드는 코드를 쭉 진행하게 되어서 쓰레드들의 작업이 완료되지 않아도 runnableTest() 메서드가 그냥 종료되어 버린 것입니다.
각 쓰레드들의 작업이 모두 끝날 때까지 메인 함수가 종료되지 않고 결과를 받고 싶을 때는 아래와 같이 Future을 사용해서 쓰레드들이 결과값을 반환할 때까지 기다리도록 구현해야 합니다.
void runnableTest() throws ExecutionException, InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(3); // 쓰레드 3개 생성
List<Integer> data = new ArrayList<>();
List<Integer> odds = new CopyOnWriteArrayList<>(); // thread-safe list
List<Future> results = new ArrayList<>(); // 작업들 결과를 저장하는 Future 리스트
for (int i = 0; i < 20; ++i) data.add(i);
data.forEach(value -> {
Runnable runnable = () -> {
System.out.printf("Thread: %s, Data: %d\n", Thread.currentThread().getName(), value);
if (value % 2 == 1) odds.add(value); // 홀수 저장
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
};
results.add(executor.submit(runnable)); // submit()을 통해 Future 객체 반환
});
for (Future result : results) {
// get()을 통해 쓰레드 결과 기다리기
System.out.println(result.get()); // Runnable은 반환값이 없는 객체이므로 null 출력
}
System.out.println("===============================");
System.out.println("size: "+odds.size());
odds.forEach(System.out::println);
executor.shutdown();
}
위와 같이 Future 객체를 이용하여 쓰레드들의 작업 결과를 반환받고, get()을 통해 결과를 기다리도록 구현하면, 모든 쓰레드가 작업을 끝나기 전까지는 (즉, data 배열의 모든 숫자들을 처리할 때까지) 메인 함수는 종료되지 않습니다.
그래서 아래와 같이 odds 배열의 결과가 잘 나오는 것을 확인할 수 있습니다. (그리고 20개의 데이터도 모두 다 출력하는 것을 확인할 수 있습니다.)

첫 번째 코드와 두 번째 코드의 차이점은 Future 객체 사용 유무도 있지만, ExecutorService의 execute()과 submit() 메서드 사용에서도 차이가 있습니다.
execute() 메소드
execute() 메서드의 경우 아래와 같이 Runnable 객체만 파라미터로 받는 단일 형태를 가집니다.
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
submit()
submit() 메소드의 경우 아래와 같은 3가지 형태를 가집니다.
public interface ExecutorService extends Executor {
...
/**
* Submits a value-returning task for execution and returns a
* Future representing the pending results of the task. The
* Future's {@code get} method will return the task's result upon
* successful completion.
*
* <p>
* If you would like to immediately block waiting
* for a task, you can use constructions of the form
* {@code result = exec.submit(aCallable).get();}
*
* <p>Note: The {@link Executors} class includes a set of methods
* that can convert some other common closure-like objects,
* for example, {@link java.security.PrivilegedAction} to
* {@link Callable} form so they can be submitted.
*
* @param task the task to submit
* @param <T> the type of the task's result
* @return a Future representing pending completion of the task
* @throws RejectedExecutionException if the task cannot be
* scheduled for execution
* @throws NullPointerException if the task is null
*/
<T> Future<T> submit(Callable<T> task);
/**
* Submits a Runnable task for execution and returns a Future
* representing that task. The Future's {@code get} method will
* return the given result upon successful completion.
*
* @param task the task to submit
* @param result the result to return
* @param <T> the type of the result
* @return a Future representing pending completion of the task
* @throws RejectedExecutionException if the task cannot be
* scheduled for execution
* @throws NullPointerException if the task is null
*/
<T> Future<T> submit(Runnable task, T result);
/**
* Submits a Runnable task for execution and returns a Future
* representing that task. The Future's {@code get} method will
* return {@code null} upon <em>successful</em> completion.
*
* @param task the task to submit
* @return a Future representing pending completion of the task
* @throws RejectedExecutionException if the task cannot be
* scheduled for execution
* @throws NullPointerException if the task is null
*/
Future<?> submit(Runnable task);
...
}
현재 코드에서 사용한 submit()은 3번째 경우입니다. 이렇게 submit() 메서드를 이용해 Future 객체를 반환하도록 한 후, Future 객체의 get() 메소드를 통해 쓰레드의 결과를 기다리도록 할 수 있습니다.
참고로, 1번째 submit()의 경우, 객체를 반환하는 Callable을 위한 메서드이고, 2번째 submit()의 경우 객체를 반환하지 않는 Runnable을 위해 직접 개발자가 어떤 값을 반환하도록 설정해 주는 메서드입니다. 즉, 만약 2번째 submit()을 아래와 같이 사용하면 get() 메서드를 호출하면 설정한 값(hello)을 반환하는 것을 확인할 수 있습니다.
data.forEach(value -> {
Runnable runnable = () -> {
System.out.printf("Thread: %s, Data: %d\n", Thread.currentThread().getName(), value);
if (value % 2 == 1) odds.add(value); // 홀수 저장
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
};
results.add(executor.submit(runnable, "hello")); // 반환값 설정
});
for (Future result : results) {
System.out.println(result.get()); // hello 출력
}
이렇게 multi threading을 구현할 때, 쓰레드들의 작업 결과를 기다리도록 하는 코드를 작성해 보았습니다. 회사에서의 병렬 처리 경험을 통해 멀티 쓰레드를 사용할 때는 주의해야 하는 점이 많고, 공부해야 하는 부분도 많다는 것을 느꼈습니다 ㅎㅎ
위 예시 코드에서 Executors.newFixedThreadPool(3)를 통해 쓰레드 풀을 생성하고 쓰레드 풀 안에 3개의 쓰레드를 생성하는 코드를 작성하였습니다.(쓰레드 풀은 매번 쓰레드를 생성하고 수거하는 것이 아닌, 쓰레드 사용자가 설정해 둔 개수만큼 미리 생성해두는 방법입니다.)
Executors.newFixedThreadPool() 외에도 다양한 방법으로 쓰레드 풀을 생성할 수 있는데, 다음 포스팅은 이렇게 Executors로 Thread Pool을 통해 Thread를 생성하는 부분과 Thread Pool을 생성할 때의 주의점에 대해서 작성해 볼 계획입니다!
'Java' 카테고리의 다른 글
| [Multi-Thread] ThreadPoolExecutor 사용법 및 주의사항 (1) | 2024.01.28 |
|---|---|
| [Multi-Thread] Executor, ExecutorService와 ThreadPoolExecutor (0) | 2024.01.27 |
| 자바의 직렬화 (Serialization) (0) | 2023.11.10 |
| Networking (네트워킹): IP주소와 URL (0) | 2023.11.05 |
| 자바의 스트림(stream) (0) | 2023.11.05 |

