Pandas를 이용한 Data Handling
DataFrame 선언하기: pd.DataFrame()
데이터 프레임을 선언하는 방법에는 여러 가지가 있습니다. 공통적으로는 pd.DataFrame()을 사용합니다.
아래 코드는 모두 같은 데이터 프레임을 나타내고 있습니다.
import numpy as np
import pandas as pd
dataset = np.array([['kor', 70], ['math', 80]])
df = pd.DataFrame(dataset, columns=['class', 'score'])
df = pd.DataFrame(data=[['kor', 70], ['math', 80]], columns=['class', 'score'])
df = pd.DataFrame({'class': ['kor', 'math'], 'score': [70, 80]})
df.head()
참고로 Series는 아래와 같이 선언합니다.
pd.Series({'idx 1': values, 'idx 2': value}, name='class')DataFrame 읽고 저장하기: pd.read_csv()/pd.to_csv()
CSV 파일로 된 데이터를 읽어올 때는 Pandas에서 제공하는 read_csv() 함수를 사용합니다.
filepath = 'dataset/data.csv'
data = pd.read_csv(filepath, na_values='NA', encoding='utf8')- na_values: csv 파일에서 null 값이 빈칸이 아닌 어떠한 string 값으로 저장된 경우 이를 인식하기 위해 사용합니다.
- encoding: 영어 외의 다른 형식의 언어로 작성된 값이 포함되어 있는 경우 해당 언어에 맞는 적절한 형식으로 인코딩해야 합니다. (한국어가 포함된 경우는 'utf8'로 인코딩합니다.)
데이터프레임을 CSV로 저장하려면 to_csv() 함수를 사용합니다.
data.to_csv('result.csv', header=True, index=True, encoding='utf8')- header: 데이터프레임의 Column 명을 저장할 지에 대한 옵션입니다.
- index: 데이터프레임의 index를 함께 저장할 지에 대한 옵션입니다.
- encoding: read_csv()와 동일합니다. 한국어 데이터일 때 'utf8' 옵션을 넣지 않는다면 글자가 깨져서 저장될 수도 있습니다.
DataFrame 인덱스 확인, 추가, 리셋
DataFrame은 index와 column 속성을 가지고 있고, 이를 통해 index, column을 수정하거나 출력할 수 있습니다. 수정할 때는 list나 numpy의 array를 사용할 수 있고, 기존 index, column 길이와 동일한 길이어야 합니다.
DataFrame.index, DataFrame.columns
아까 생성했던 데이터 프레임으로 확인해 보겠습니다. df.index에 원하는 인덱스 값 배열을 넣어주면 아래와 같이 인덱스가 변경되는 것을 볼 수 있습니다.

list(df.index) # [0, 1]
df.index = ['A', 'B']
df.index # Index(['A', 'B'], dtype='object')df를 출력해 보니 아래와 같이 인덱스가 변경되었음을 알 수 있습니다.

column 명을 변경하려면 index와 동일한 방법은 df.columns에 배열을 넣어주면 됩니다. 혹은 아래와 같은 방법을 사용합니다. (sklearn 라이브러리에서 제공하는 iris 데이터를 사용했습니다.)
DataFrame.columns.str.replace('기존문자', '대체할 문자')

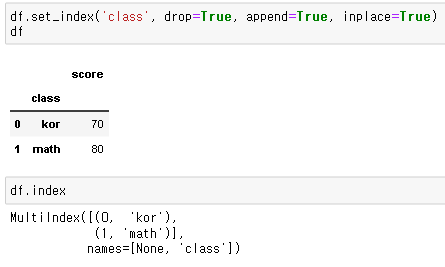
DataFrame.set_index(keys, drop=True, append=False, inplace=True)
위 함수를 사용하면 DataFrame 내의 열을 인덱스로 변경할 수 있습니다.
- keys: 인덱스로 사용하고자 하는 칼럼의 이름을 문자형으로 입력
- drop: 인덱스로 세팅한 컬럼을 DataFrame 내에서 삭제할지 결정
- append: 기존에 존재하던 인덱스 삭제할지, 컬럼으로 추가할지 결정
- inplace: 원본 객체를 변경할지 결정

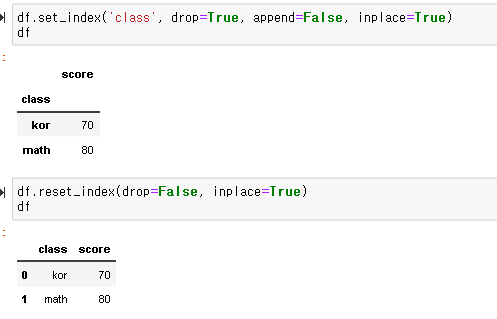
DataFrame.reset_index(drop=False, inplace=False)
위 함수를 사용하면 인덱스를 0부터 시작하는 정수로 재설정할 수 있습니다. 보통 데이터프레임을 특정 컬럼 값을 기준으로 정렬했거나 2개의 데이터 프레임을 join 했거나, 특정 컬럼을 기준으로 groupby 함수를 사용했을 경우 등의 이유로 인덱스가 중구난방으로 섞이는 경우가 있는데 이 경우에 많이 사용합니다.
- drop: 기존 인덱스를 DataFrame 내에서 삭제할지, 컬럼으로 추가할지 결정
- inplace: 원본 객체를 변경할지 결정
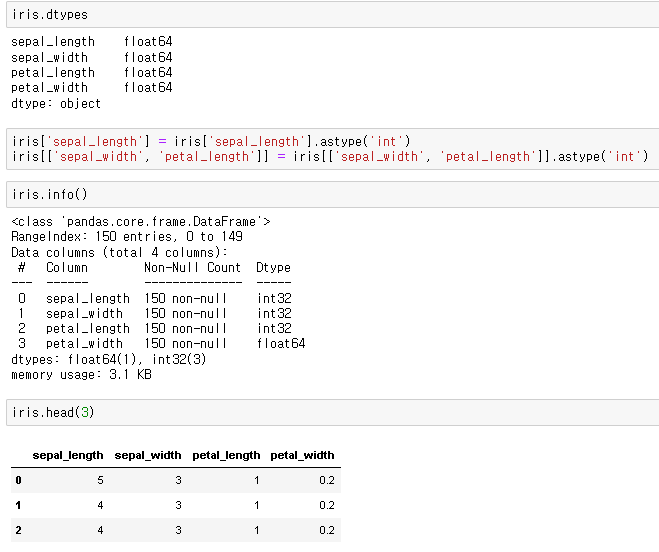
DataFrame 컬럼의 데이터 타입 확인
Dataframe 컬럼은 다양한 타입을 가집니다. 데이터프레임이 데이터가 어떤 타입을 가지는 지 확인하려면 dtypes 속성, 혹은 DataFrame.info()를 사용하여 확인할 수 있습니다.
row/column 선택, 추가, 삭제
데이터프레임의 인덱스와 컬럼명을 이용하여 데이터프레임의 특정 데이터를 추출할 수 있습니다.
대부분 사용하는 방법은 iloc[ ]과 loc[ ] 속성입니다. 이 둘에 대해서 알아보겠습니다.
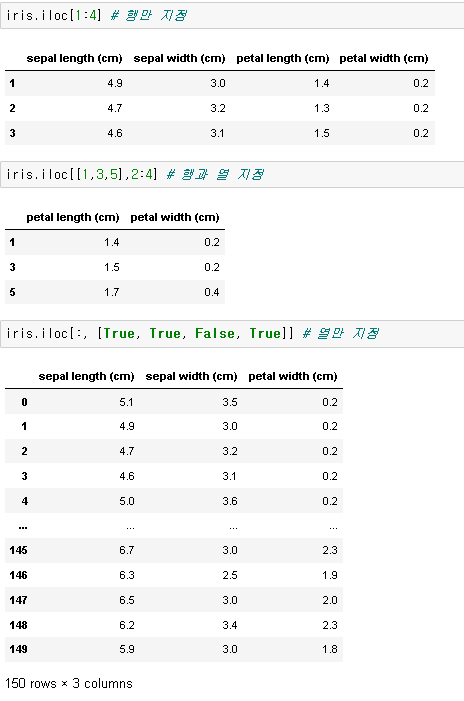
DataFrame.iloc[row, column]
위 함수는 정수로 된 위치 기반 인덱스(integer location)로 행과 열을 선택할 때 사용합니다. 인수로는 정수, 리스트, 슬라이싱, boolean array가 들어갈 수 있습니다.
DataFrame.loc[row, column]
Label, 즉 인덱스의 이름 혹은 컬럼명으로 행과 열을 선택할 때 loc[ ] 을 사용합니다. iloc[ ] 과 마찬가지로 정수, 리스트, 슬라이싱, boolean array가 인수로 들어갈 수 있습니다.
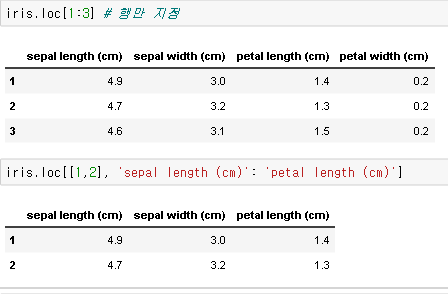
loc[ ] 에서 슬라이싱 start:end를 사용할 때, start부터 end까지로, end를 포함한다는 것에 주의해야 합니다!
밑에서 알 수 있듯이 iris.loc[1:3]은 위에서 보았던 iris.iloc[1:4]와 같다는 것을 알 수 있습니다.
데이터프레임에 한 행을 추가하는 것은 append()를 사용합니다. append의 인수로는 DataFrame, Series, Dictionary 가 들어갑니다.
Series가 인수일 경우, Series의 name 속성이 추가되는 행의 index가 됩니다.
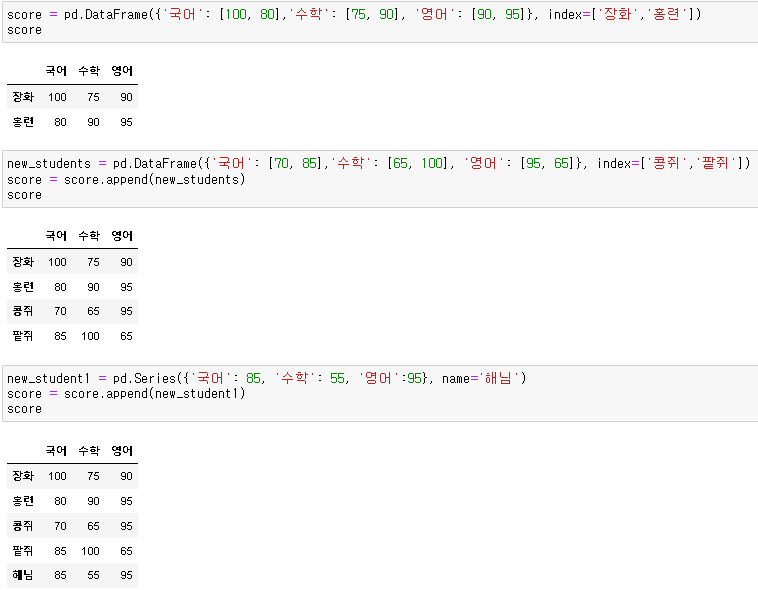
Dictionary 자료형을 사용하여 행을 추가할 경우, 인덱스로 사용할 정보가 없으므로 ignore_index 인자를 True로 설정하지 않으면 오류가 발생합니다. ignore_index=True로 설정할 경우, 기존의 인덱스도 전부 사라지기 때문에 주의해서 사용해야 합니다.

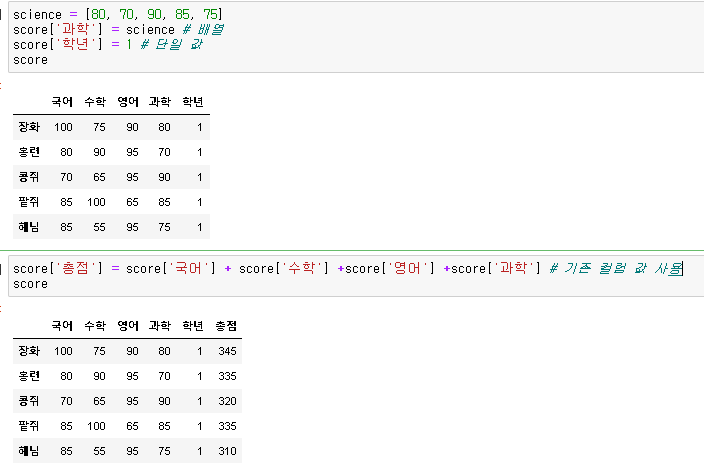
데이터프레임에 열을 추가하는 것은 간단합니다. 단일 값 혹은 데이터프레임 행의 수와 같은 길이의 배열을 새로운 컬럼에 대입하여 생성할 수 있습니다. 혹은 기존 데이터프레임에 존재하던 컬럼 값을 이용하여 생성할 수도 있습니다.
행이나 열을 삭제하고 싶다면 drop()을 사용하여 삭제할 수 있습니다. 하지만 행과 열을 동시에 삭제할 수는 없습니다.
DataFrame.drop(index=None, columns=None, inplace=False)
- index: 삭제할 행의 인덱스 혹은 인덱스 리스트 지정
- columns: 삭제할 컬럼의 이름 혹은 컬럼명의 리스트 지정
- inplace: False일 경우 작업 수행의 결과를 복사본으로 반환, True이면 작업을 수행하고 None 반환
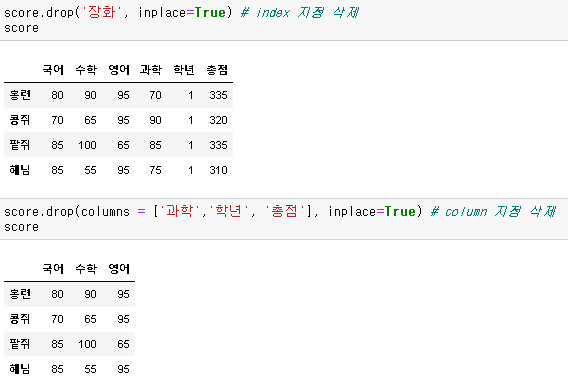
위에서 보시다시피 행(index)을 지정하여 삭제할 경우 'index=' 부분은 생략이 가능합니다.
여기까지 판다스의 데이터프레임을 다루는 데 기본적인 내용을 알아보았습니다.
다음 포스팅에서는 데이터프레임을 이용하여 어떻게 조건에 맞게 데이터를 수정하고 탐색하는지 알아보겠습니다.
출처
[데싸라면, 빨간색 물고기, 자투리코드] 파이썬 한권으로 끝내기: 데이터분석전문가(ADP) + 빅데이터분석기사 실기대비, 시대고시기획(2022), p15-32)