조건식을 이용한 데이터 탐색 및 결측값 다루기
데이터프레임의 각 컬럼에서는 조건문의 조건에 맞는 값을 가진 행을 탐색하거나 수정할 수 있습니다. 기본적으로는 아래와 같은 형식으로 조건식을 탐색합니다.
DataFrame[조건식]
조건식이 1개일 경우 위 형식에 그대로 조건식을 넣어서 데이터를 필터링할 수 있습니다. 만약 조건이 여러 개라면 &(AND 연산자), | (OR 연산자)를 사용하여 연결합니다.

또한, 아래와 같은 방법으로도 필터링이 가능합니다. 이를 이용하면 원하는 컬럼을 추출하여 데이터를 수정할 수 있고 새로운 컬럼을 생성할 수도 있습니다.
df.loc[조건문, '추가/변경할 컬럼명']

위 결과에서 볼 수 있듯이, 6번 행을 추출하여 추출하고자 하는 컬럼의 데이터를 컬럼명을 통해 추출하고, 그 데이터를 오른쪽에 있는 ['별님', 50, 60]이라는 배열 값으로 수정하는 코드입니다.
이제 조건식을 이용하여 특정 컬럼 데이터를 생성 및 수정해 보겠습니다.

'합격'이라는 컬럼명은 원래 없었던 것이기 때문에 데이터프레임에 새로 생성된 것을 볼 수 있습니다. 또한 조건에 의해 'Pass' 값이 들어가지 못하는 데이터는 NaN으로 채워졌습니다.
이제 이 NaN 값을 예쁘게 다듬어 보겠습니다. 즉, 컬럼 데이터를 수정해 보겠습니다.

만약, 하나의 컬럼에 여러 개 조건에 따라 특정 값을 반환해야 하는 경우는 numpy의 selec()을 사용할 수 있습니다.
np.select(조건들 리스트, 반환해야 하는 특정 값들, default = 조건들에 부합하지 않을 때 반환해야 하는 값)

결측값 다루기
결측값은 값이 존재하지 않는 것을 의미합니다. 파이썬에서 None, np.NaN, pd.NaT 등의 방식으로 표현됩니다.
먼저 이러한 결측값을 탐색해 보겠습니다.
결측값 탐색: isna(),isnull()
결측이 아닌 값 탐색: notna(), notnull()
위 함수를 이용하여 데이터프레임에 결측값이 얼마나 있는지 sum() 함수를 결합하여 확인할 수 있습니다. sum()은 열 합계, sum(1)은 행 합계를 의미합니다.

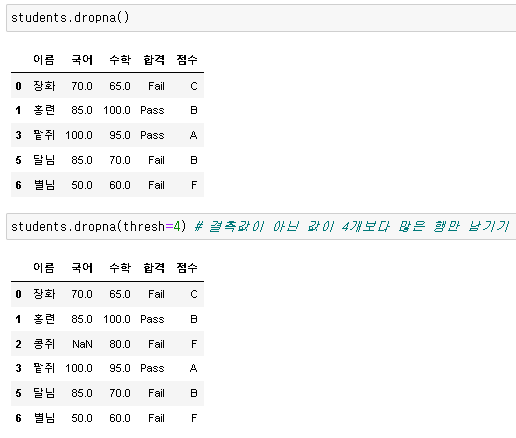
결측값 제거: dropna()
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
- axis: 0 또는 'index'이면 결측값이 포함된 행을 삭제, 1 또는 'columns'이면 결측값이 포함된 열 삭제
- how: 'any'이면 결측값이 존재하는 모든 행/열 삭제, 'all'이면 모든 값이 결측값일 때 삭제
- thresh: 정수를 넣으면 결측값이 아닌 값이 그보다 많을 때 행 또는 열을 유지
- subset: 어떤 레이블에 결측값이 존재하면 삭제할지 정의
- inplace: True이면 제자리에서 작업 수행 후 None 반환
결측값 대체: fillna()
DataFrame.fillna(value = None, method = None, axis = None, inplace = False, limit = None)
- value: 단일 값 혹은 dict/Series/DataFrame 형식으로 대체할 값 직접 입력
- method: 'pad', 'fill'이면 이전 값으로 채우고, 'backfill' / 'bfill' 이면 다음에 오는 값으로 채움
- axis: 0 또는 'index' 이면 행 방향으로 채우고, 1 또는 'column' 이면 열 방향으로 채움
- limit: method 인자를 지정한 경우 limit으로 지정한 개수만큼만 대체할 수 있음
새로운 데이터프레임을 생성하여 결측값을 채워보겠습니다.
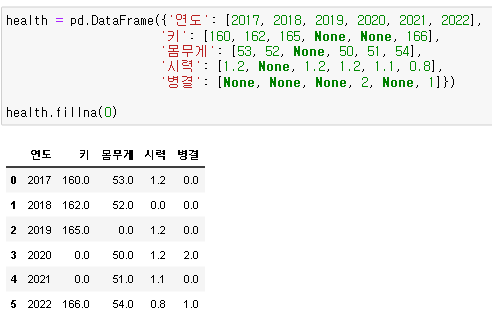
fillna(0)을 통해 결측값 None 부분들이 모두 0.0으로 채워진 것을 확인할 수 있습니다.
또한, 아래와 같이 데이터 특성에 맞게 각 컬럼 값의 평균값으로 채워 넣을 수도 있습니다.

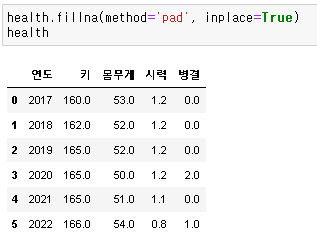
마지막으로, method 속성을 사용해 보겠습니다. 'pad'를 넣음으로써 각 결측값의 이전값들이 결측값을 채워 넣고 있습니다.
출처
[데싸라면, 빨간색 물고기, 자투리코드] 파이썬 한권으로 끝내기: 데이터분석전문가(ADP) + 빅데이터분석기사 실기대비, 시대고시기획(2022), p33-40)