Reactor의 Scheduler
비동기 프로그래밍을 위해 사용되는 스레드, 즉 Reactor Sequence에서 사용되는 스레드를 관리해 주는 관리자 역할을 합니다. Reactor의 Scheduler는 관리자의 역할로서 어떤 스레드에서 무엇을 처리할지 제어합니다.
자바에서 멀티 스레드를 관리하는 것은 까다롭습니다. 스레드 간의 경쟁 조건 등을 신중하게 고려해서 코드를 작성해야 하는데 이를 통해 예상치 못한 오류 발생할 가능성 높습니다.
Reactor의 Scheduler를 통해서 이런 문제를 최소화할 수 있습니다. 우선, Reactor의 Scheduler를 사용하면 코드 자체가 매우 간결해집니다. 그리고, Scheduler가 스레드의 제어를 대신해 주기 때문에 개발자가 직접 스레드를 제어해야 하는 부담이 적어집니다.
Operator
Reactor에서 Scheduler는 아래와 같은 Scheduler 전용 Operator를 통해 사용할 수 있습니다.
- subscribeOn()
- publishOn()
- parallel()
각각의 Operator에 대해서 알아보겠습니다.
1. subscribeOn()
이름처럼 구독이 발생한 직후 실행될 스레드 지정해 주는 역할을 합니다.
구독이 발생하면 원본 Publisher가 데이터를 최초 emit 하기 시작합니다.
따라서, subscribeOn() 사용하면, 원본 Publisher의 동작을 수행하기 위한 스레드를 지정한다는 의미를 가진다고 생각할 수 있습니다.
@Slf4j
public class Main {
public static void main(String[] args) throws InterruptedException {
Flux.fromArray(new Integer[]{1,3,5,7})
.subscribeOn(Schedulers.boundedElastic())
.doOnNext(data->log.info("# doOnNext: {}", data))
.doOnSubscribe(subscription -> log.info("# doOnSubscribe"))
.subscribe(data->log.info("# onNext:{}", data));
Thread.sleep(500L);
}
}
아래 결과를 보면 구독이 발생한 직후 실행되는 Operator는 별도의 스레드에서 실행됨을 확인할 수 있습니다. (doOnSubscribe()는 구독이 발생한 그 시점에 추가적인 어떤 처리가 필요할 경우 사용하는 Operator로 구독이 발생한 시점 후가 아니기 때문에 Main 스레드에서 실행되고 있습니다.)
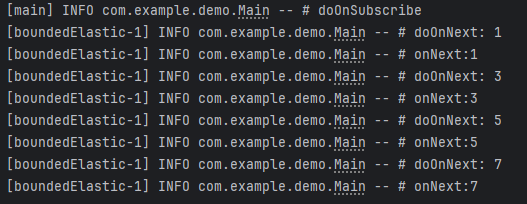
2. publishOn()
Downstream으로 Signal을 전송할 때 실행되는 스레드를 제어합니다.
즉, publishOn()을 기준으로 아래쪽인 Downstream의 실행 스레드를 변경합니다. subscribeOn() 마찬가지로 파라미터로 Scheduler를 지정함으로써 해당 Scheudler의 특성을 가진 스레드를 지정할 수 있습니다.
@Slf4j
public class Main {
public static void main(String[] args) throws InterruptedException {
Flux.fromArray(new Integer[]{1,3,5,7})
.doOnNext(data->log.info("# doOnNext: {}", data))
.doOnSubscribe(subscription -> log.info("# doOnSubscribe"))
.publishOn(Schedulers.parallel())
.subscribe(data->log.info("# onNext:{}", data));
Thread.sleep(500L);
}
}
실행 결과를 보면, onNext의 경우 publishOn() 이 Upstream에 추가되었기 때문에, parallel-1 스레드에서 실행되었습니다.

3. parallel()
subscribeOn(), publishOn()은 동시성(Concurrency)을 가지는 논리적인 스레드에 해당한다면, parallel()은 병렬성(Parrellel)을 가지는 물리적인 스레드에 해당합니다.
parallel()은 라운드 로빈 방식으로 CPU 코어 내부의 스레드 개수만큼의 스레드를 병렬로 실행합니다. 예를 들어, 4 코어 8 스레드 CPU라면 8개의 스레드를 병렬로 실행하도록 해줍니다.
@Slf4j
public class Main {
public static void main(String[] args) throws InterruptedException {
Flux.fromArray(new Integer[]{1,2,3,4,5,6,7,8,9,10})
.parallel()
.runOn(Schedulers.parallel()) // 중요!
.subscribe(data->log.info("# onNext:{}", data));
Thread.sleep(500L);
}
}
위 코드에 runOn()이라는 Operator도 추가되었습니다. parallel() Operator만 추가한다고 해서 emit 되는 데이터를 병렬로 처리하지 않습니다. parallel()는 emit 되는 데이터를 CPU의 물리적인 스레드 수에 맞게 사전에 골고루 분배하는 역할만 하며, 실제로 병렬 작업을 수행할 스레드 할당은 runOn() Operator가 담당합니다.
현재 제 PC에는 8개의 물리적인 스레드가 있어 8개의 스레드로 병렬 처리가 이루어지고 있음을 확인할 수 있습니다.
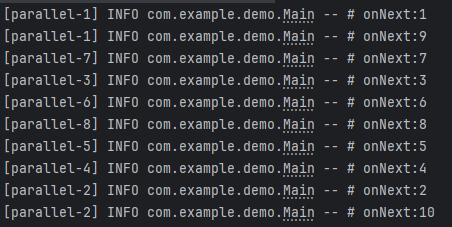
추가로, parallel() 에 파라미터로 사용하고자 하는 스레드의 개수를 지정해 줄 수 있습니다.
Flux.just(1,2,3,4,5,6,7,8,9,10)
.parallel(4) // 4개의 스레드만 병렬로 실행
.runOn(Schedulers.parallel())
.subscribe(data->log.info("# next: {}", data));
publishOn, subscribeOn 혼합 사용
아래와 같이 subscribeOn()과 publishOn()을 2개 사용해 보았습니다.
@Slf4j
public class Main {
public static void main(String[] args) throws InterruptedException {
Flux.just(1,2,3,4,5,6)
.subscribeOn(Schedulers.boundedElastic())
.doOnNext(data->log.info("# doOnNext: {}", data))
.publishOn(Schedulers.parallel()) // 1
.map(d->d*2)
.doOnNext(data->log.info("# doOnNext MAP: {}", data))
.publishOn(Schedulers.parallel()) // 2
.subscribe(data->log.info("# next: {}", data));
Thread.sleep(500L);
}
}
결과를 예상해보면, subscribeOn()으로 지정된 스레드는 구독 후에 발생하는 log인 첫 번째 doOnNext() 메서드에서 사용될 것이라 생각할 수 있습니다. 그 후, 첫 번째 publishOn()으로 인해 데이터 소스에 2를 곱한 값을 출력하는 log인 doOnNext MAP에서 parallel 스레드를 사용할 것입니다. 마지막으로 두 번째 publishOn()으로 subscriber가 구독 후 출력하는 log인 next 로그가 다른 parallel 스레드에서 실행될 것입니다.
아래 결과를 통해 확인해 보세요!

Reactor에서 지원하는 Scheduler에는 어떤 것이 있는지도 알아보겠습니다.
Scheduler 종류
아래 그림처럼 Reactor에서는 다양한 Scheduler를 지원하고 있습니다. 하나씩 알아보겠습니다.
Schedulers.immediate()
별도의 스레드를 추가적으로 생성하지 않고, 현재 존재하는 스레드에서 작업을 처리하고자 할 때 사용합니다.
@Slf4j
public class Main {
public static void main(String[] args) throws InterruptedException {
System.out.println("=============Immediate===========");
Mono.just("Hello")
.subscribeOn(Schedulers.immediate())
.doOnNext(data->log.info("# onNext: {}", data))
.subscribe(data->log.info("# next: {}", data));
Thread.sleep(500L);
}
}
실행결과

Schedulers.single()
스레드를 하나만 생성해서 Scheduler가 제거되기 전까지 재사용하는 방식입니다.
다수의 작업을 하나의 스레드로 처리해야 되므로, 지연 시간이 짧은 작업을 처리하는 것이 효과적입니다.
@Slf4j
public class Main {
public static void main(String[] args) throws InterruptedException {
System.out.println("=============Single===========");
// Single Scheduler 예
doTask("task1")
.subscribe(data->log.info("# onNext: {}", data));
doTask("task2")
.subscribe(data->log.info("# onNext: {}", data));
}
private static Mono<String> doTask(String taskName){
return Mono.just("Hello")
.subscribeOn(Schedulers.single())
.map(String::toUpperCase)
.doOnNext(data->log.info(" # onNext: {}", data));
}
}
실행 결과
2개의 task를 실행했는데 동일한 스레드에서 수행되고 있음을 확인할 수 있습니다.
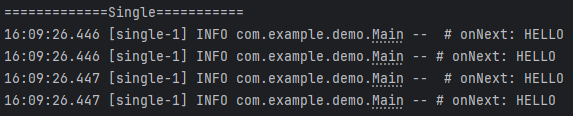
Schedulers.newSingle()
Schedulers.single()과 달리, 호출할 때마다 매번 새로운 스레드 하나를 생성합니다.
메서드의 첫 번째 파라미터에는 생성할 스레드의 이름을 지정하고, 두 번째 파라미터에는 이 스레드를 데몬(Daemon) 스레드로 동작하게 할지 여부를 설정할 수 있습니다.
데몬 스레드: 보조 스레드, 주 스레드가 종료되면 자동으로 종료되는 특징
따라서, 두 번째 파라미터 값이 true 인 경우, main 스레드가 종료가 되면 생성된 스레드도 자동으로 종료되도록 설정됩니다.
@Slf4j
public class Main {
public static void main(String[] args) throws InterruptedException {
System.out.println("=============newSingle===========");
// NewSingle Scheduler 예
Mono.just("Hello")
.subscribeOn(Schedulers.newSingle("myScheduler", true))
.doOnNext(data->log.info("# onNext: {}", data))
.subscribe(data->log.info("# next: {}", data));
Thread.sleep(500L);
}
}
실행 결과

Schedulers.boundedElastic()
ExecutorService 기반의 스레드 풀(Thread pool)을 생성한 후, 그 안에서 정해진 수만큼의 스레드를 사용해서 작업을 처리하고, 작업이 종료된 스레드는 반납하여 재사용하는 방식입니다.
기본적으로, CPU 코어 수 x 10 만큼의 스레드를 생성하여 풀에 저장합니다.
풀에 있는 스레드가 모두 작업을 처리하고 있으면 이용 가능한 스레드가 생길 때까지 최대 100,000개의 작업이 큐에서 대기할 수 있습니다.
이 Scheduler는 Blocking I/O 작업 처리에 최적화 되어 있습니다. 왜냐하면 실행 시간이 긴 blocking I/O 작업이 포함된 경우, 다른 Non-Blocking 처리에 영향을 주지 않도록 전용 스레드를 할당해서 Blocking I/O 작업을 처리할 수 있어 작업 처리 시간 효율적 사용할 수 있기 때문입니다.
Schedulers.parallel()
Non-Blocking I/O 에 최적화되어 있는 Scheduler로 CPU 코어 수만큼의 스레드를 생성합니다.
Schedulers.fromExectutorService()
기존에 이미 사용하고 있는 ExecutorService가 있다면 이로부터 Scheduler를 생성하는 방식입니다. (Reactor에서는 이 방식을 권장하지 않습니다.)
Schedulers.newXXX()
Schedulers.single(), Schedulers.boundedElastic(), Schedulers.parallel()은 Reactor에서 제공하는 디폴트 Scheduler 인스턴스를 사용합니다. 필요하다면 Schedulers.newSingle(), Schedulers, newBoundedElastic(), Schedulers.newParallel() 메서드를 사용해서 새로운 Scheduler 인스턴스를 생성할 수 있습니다.
즉, 스레드 이름, 생성 가능한 디폴트 스레드 개수, 스레드의 유휴 시간, 데몬 스레드로의 동작 여부 등을 직접 지정해서 커스텀 스레드 풀을 새로 생성할 수 있습니다.
'Spring Boot > Webflux' 카테고리의 다른 글
| Context (1) | 2024.10.15 |
|---|---|
| Cold sequence와 Hot sequence (0) | 2024.10.12 |
| Reactor란? (1) | 2024.10.11 |


