문자열 검색 알고리즘으로 많이 등장하는 KMP 알고리즘에 대해서 알아보겠습니다. KMP는 Knuth Morris Partt의 줄임말로 이 알고리즘을 발견한 사람 이름을 딴 것입니다.
어떤 문자열 A에 문자열 B가 있는지 확인하려면 단순하게 A 문자열(길이 N)과 B 문자열(길이 M)을 하나하나 비교한다면, 시간 복잡도는 O(NM)가 될 것입니다. KMP 알고리즘은 이 시간 복잡도 보다 더 효율적으로 줄여 O(N+M) 만에 문자열을 검색할 수 있는 방법입니다. 어떻게 획기적으로 시간 복잡도를 줄일 수 있었는지 KMP에 대해서 알아보겠습니다.
먼저, KMP 알고리즘을 알기 전에 미리 알아야 할 사전 지식을 살펴보겠습니다.
사전지식
접두사(Prefix)와 접미사(Suffix)
우선 접두사와 접미사가 무엇인지 확인해 보겠습니다. 아래와 같이 BANANA라는 문자열이 있을 때, 접두부는 문자열의 왼쪽에서부터 시작되는 부분 문자열, 접미부는 문자열의 오른쪽에서부터 시작되는 부분 문자열입니다.
(단, 접두사와 접미사는 전체 문자열이 될 수 없습니다.)

경계
다음은 경계에 대해서 알아보겠습니다.
경계란, 아래와 같이 '접두부'와 '접미부'가 동일할 때, 그 접두부 혹은 접미부를 가리킵니다. 그리고 그 경계의 길이를 나타내는 배열 P [i]를 통해 문자열의 (0~i)까지의 부분문자열에서의 경계의 길이를 표시했습니다.
여기서 주의할 점은 ABAABA 부분 문자열에서처럼 경계가 여러 개(ABAABA: A, ABAABA: ABA)가 나타날 수 있습니다. 이때, 경계를 최대 길이를 가지는 접두사와 접미사로 정의합니다.
이렇게 주어진 문자에 대한 접두사, 접미사, 경계에 대해서 알게 되었으니 본격적으로 KMP 알고리즘에 대해서 알아보겠습니다.
KMP 알고리즘
알고리즘이 어떻게 이루어지는지 순서대로 살펴보겠습니다.
본문 ABCDABCDABDE 가 있을 때, 문자열 ABCDABD를 본문에서 찾는다고 가정합니다.
1. 먼저 찾고자 하는 대상 문자열 ABCDABD를 본문 처음에 둡니다.
2. 본문과 문자열을 비교하여 일부가 일치하지 않는다면, 불일치한 부분을 제외한 직전까지 일치하는 패턴에서 최대 길이의 경계를 찾습니다.
위에서 일치하는 패턴에서의 최대 길이의 경계를 찾아보겠습니다. 아래와 같이 최대 길이를 갖는 AB를 경계로 선택합니다.
3. 선택한 경계에 일치하는 패턴의 접두부를 패턴의 접미부의 시작 문자열까지 이동시킵니다.
즉, 일치하는 패턴의 길이에서 경계의 길이를 뺀 값만큼 이동시켜 줍니다. (6 - 2 = 4)
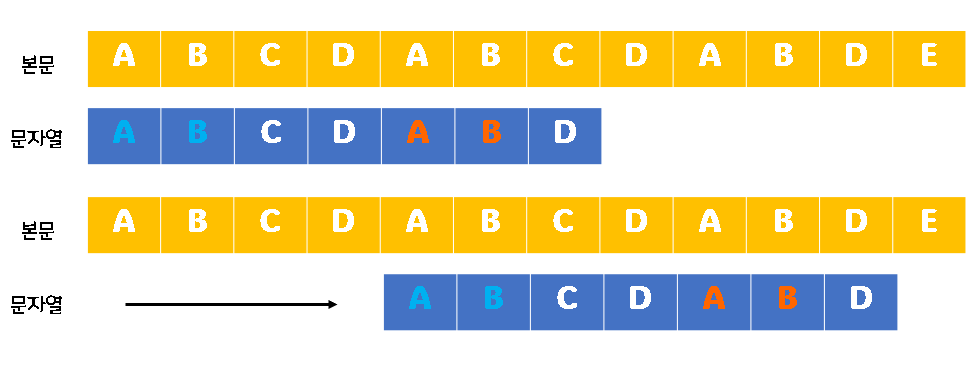
위 그림에서 문자열에 일치하는 패턴을 본문에서 찾았음을 확인할 수 있습니다. 위 예시는 이동 1번 만에 일치 패턴을 찾았지만 그렇지 않은 경우에는 1번부터 3번까지의 과정을 본문에서 문자열을 찾을 때까지 혹은 본문이 끝날 때까지 반복합니다.
만약, 2번에서 경계를 찾지 못했다면 처음으로 불일치했던 부분까지 패턴을 이동시키면 됩니다. 그리고 1번부터 과정을 반복합니다.
이렇게 최대 경계를 이용하여 문자열을 찾으면 Brute Force (O(NM))보다 효율적으로 찾을 수 있습니다. 하지만 여기서 매번 움직일 때마다 경계를 찾으려고 하면 알고리즘의 효율성이 매우 떨어질 것입니다. 이를 해결하기 위해 이동할 때 얼마나 이동해야 하는지 참고할 수 있는 이동 경로 테이블을 만들어야 합니다.
이동 경로 테이블
이 테이블에는 어떤 정보가 저장되어야 할까요?.
먼저 위에서 문자열의 이동 거리를 구할 때 (알고리즘 3번 과정) 아래의 2가지 정보를 활용했습니다.
- 일치하는 패턴 길이: 본문에서 문자열의 일부가 불일치할 때, 불일치 직전까지의 패턴의 길이 (알고리즘 1번 과정)
- 최대 경계 길이: 일치하는 패턴에서의 찾은 경계들 중 최대 길이 (알고리즘 2번 과정)
위 2가지 정보를 통해 우리는 이동 거리를 일치하는 패턴 길이 - 최대 경계 길이만큼 이동해 주었습니다. 따라서 아래 그림과 같이 이동 경로 테이블에는 위 2가지 정보를 저장하여 문자열에서 불일치하는 문자 위치에 따라 (일치하는 패턴의 길이에 따라) 이동거리를 바로바로 구해 줄 수 있을 것입니다.

그럼 위의 예시(문자열 ABCDABD)를 재사용하여 일치 패턴 길이에 따른 최대 경계 길이를 구해보겠습니다.
1. 일치 패턴 길이가 0일 때:
최대 경계 길이는 0일 것입니다. 하지만, 최대 경계 길이를 0으로 설정하면 이동거리가 0이 되어 절대 이동하지 않겠죠? 따라서, 이 경우에는 문자열이 1칸만 이동해야 하므로 최대 경계 길이를 -1로 설정합니다.
2. 일치 패턴 길이가 1일 때: A
경계가 없으므로 최대 경계 길이는 0입니다.
3. 일치 패턴 길이가 2일 때: AB
경계가 없으므로 최대 경계 길이는 0입니다.
4. 일치 패턴 길이가 3일 때: ABC
경계가 없으므로 최대 경계 길이는 0입니다.
5. 일치 패턴 길이가 4일 때: ABCD
경계가 없으므로 최대 경계 길이는 0입니다.
6. 일치 패턴 길이가 5일 때: ABCDA
경계가 A 하나 이므로 최대 경계 길이는 1입니다.
7. 일치 패턴 길이가 6일 때: ABCDAB
경계가 AB 하나 이므로 최대 경계 길이는 2입니다.
8. 일치 패턴 길이가 7일 때: ABCDABD
경계가 없으므로 최대 경계 길이는 0입니다. 일치 패턴의 길이가 7이라는 뜻은 문자열과 완벽히 일치하는 위치를 본문에서 찾았다는 의미이지만, 그 뒤에도 패턴과 일치하는 경우가 더 있을 수 있으므로 최대 경계 길이를 계산하여 넣어주어야 합니다.
위의 정보를 이용하여 이동 거리 테이블을 완성한 모습입니다.

따라서 앞에서 배운 KMP 알고리즘과 위의 이동 거리 테이블을 이용하여 알고리즘을 수행하면 O(N+M)만에 본문 내의 패턴 매칭을 수행할 수 있습니다. 위 과정을 소스코드로 구현해 보겠습니다.
코드 구현 1
아래코드는 백준 1786 찾기 (https://www.acmicpc.net/problem/1786) 문제를 기반으로 코드를 작성하였습니다. (시간초과)
#include<stdio.h>
#include<string.h>
char T[1000005], P[1000005];
int pi[1000005];
int ans[1000005];
void makeTable(int len) {
int borderLen = -1, matchedPatternLen = 0;
pi[matchedPatternLen++] = borderLen++; // pi[0] = -1
while (matchedPatternLen < len) {
while (borderLen > 0 && P[matchedPatternLen] != P[borderLen]) {
borderLen = pi[borderLen];
}
if (P[borderLen] == P[matchedPatternLen]) pi[matchedPatternLen + 1] = ++borderLen;
++matchedPatternLen;
}
}
void KMP(int arrLen, int patternLen) {
int matchingCnt = 0;
int moveDistance = 0, arrIdx = 0, patternIdx = 0;
while ((arrIdx + moveDistance) + patternLen <= arrLen) {
while (T[arrIdx + moveDistance] == P[patternIdx]) {
++patternIdx; // 일치 개수 증가
++arrIdx; // 본문(arr) 가리키는 인덱스 증가
if (patternIdx == patternLen) { // 문자열 매칭 성공
ans[matchingCnt++] = moveDistance + 1;
break;
}
}
moveDistance = moveDistance + (patternIdx - pi[patternIdx]); // 이동거리
patternIdx = 0;
arrIdx = 0;
}
printf("%d\n", matchingCnt);
for (int i = 0; i < matchingCnt; ++i) printf("%d ", ans[i]);
}
int main() {
int a;
scanf("%[^\n]s", T);
scanf("%c", &a);
scanf("%[^\n]s", P);
int len = strlen(P);
makeTable(len);
KMP(strlen(T), len);
}
그런데 위와 같이 문제를 푸니까 시간 초과가 납니다... 왜 시간초과가 나는지 아래 그림을 통해 확인해 보겠습니다.
아까 사용하였던 본문과 문자열입니다. KMP 함수 내에서 문자열을 이동시키고 다시 문자열 처음부터 본문과 비교하게 됩니다. 하지만 잘 생각해 보면 경계 부분인 AB를 다시 본문과 비교할 필요가 없습니다. 경계이므로 문자열을 이동시킨 후 접두부 AB는 본문과 같음이 자명하기 때문입니다. 따라서 C부터 본문과 비교하도록 코드를 개선하면 됩니다.
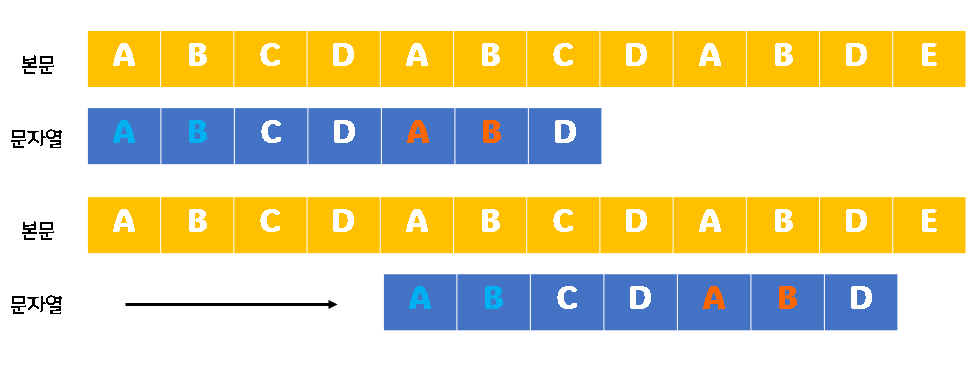
이를 위해서 문자열을 직접 옮기기보다 (즉, patternIdx 변수를 0부터 시작하는 것보다) 문자열 패턴에서 비교를 시작하고자 하는 위치 (위 그림에서 문자 C의 위치)를 cnt 변수에 저장하여 알고리즘을 수행합니다.
위 방법을 구현한 코드입니다. 이렇게 구현하면 위의 코드보다 조금 더 빠르게 KMP 알고리즘을 돌릴 수 있어 시간 안에 코드가 통과합니다.
코드 구현 2
#include<stdio.h>
#include<string.h>
char T[1000005], P[1000005];
int pi[1000005];
int ans[1000005];
void makeTable(int len) {
int borderLen = -1, matchedPatternLen = 0;
pi[matchedPatternLen++] = borderLen++; // pi[0] = -1
while (matchedPatternLen < len) {
while (borderLen > 0 && P[matchedPatternLen] != P[borderLen]) {
borderLen = pi[borderLen];
}
if (P[borderLen] == P[matchedPatternLen]) pi[matchedPatternLen + 1] = ++borderLen;
++matchedPatternLen;
}
}
void KMP(int arrLen, int patternLen) {
int matchingCnt = 0;
int arrIdx = 0, patternIdx = 0;
while (arrIdx < arrLen) {
while (patternIdx != 0 && T[arrIdx] != P[patternIdx])
patternIdx = pi[patternIdx]; // 경계부분을 점프하여 비교가 필요한 위치로 이동
if (T[arrIdx] == P[patternIdx]) {
++patternIdx; // 일치 개수 증가
++arrIdx; // 본문(arr) 가리키는 인덱스 증가
if (patternIdx == patternLen) { // 문자열 매칭 성공
ans[matchingCnt++] = arrIdx - patternLen + 1;
// 문자열 끝까지 갔으므로 다시 시작(마찬가지로 경계 점프)
patternIdx = pi[patternIdx];
//break;
}
}
else arrIdx++;
}
printf("%d\n", matchingCnt);
for (int i = 0; i < matchingCnt; ++i) printf("%d ", ans[i]);
}
int main() {
int a;
scanf("%[^\n]s", T);
scanf("%c", &a);
scanf("%[^\n]s", P);
int len = strlen(P);
makeTable(len);
KMP(strlen(T), len);
}
위 코드를 자세히 살펴보면 makeTable과 KMP 내의 과정이 동일함을 알 수 있습니다.
즉, makeTable 함수도 KMP의 특징인 접두사와 접미사를 활용하여 경계의 길이를 구한다는 것을 알 수 있습니다. 다른 점이 있다면, KMP는 문자열과 본문을 비교하는 반면, makeTable은 같은 문자열끼리 비교하여 경계를 찾는다는 점이라고 할 수 있겠습니다.
관련문제
11585번:속타는 저녁 메뉴 (acmicpc.net)
참고
https://bowbowbow.tistory.com/6
'Algorithms' 카테고리의 다른 글
| C언어 - 문자열 탐색, 비교 구현해보기 (0) | 2023.12.09 |
|---|---|
| 비트 연산 활용 (4) | 2023.12.03 |
| 그리디 알고리즘 (Greedy)과 다이나믹 프로그래밍 (DP) (0) | 2023.10.18 |
| Euler's Phi (오일러 파이 함수) (2) | 2023.09.09 |
| LCA - 최소 공통 조상 (0) | 2023.08.27 |

