728x90
반응형
Feature Extraction: 데이터의 feature를 어떻게 유용하게 만들 것인가
Feature Selection: 데이터에서 유용한 피처를 어떻게 선택할 것인가
feature selection 방법론
1. Filter method: feature 간 관련성 측정 (correlation)
2. Wrapper method: Feature subset의 유용성 측정
3. Embedded method: Feature subset의 유용성 측정하지만 내장 metric 사용
1. Filter Method
- 가장 많이 사용
- 통계적 측정 방법 사용: feature 간 상관관계 파악
- 높은 상관계수(영향력)을 가지는 feature 사용
information gain, chi-square test, fisher score, correlation coefficient(heatmap 시각화),
variance threshold
2. Wrapper Method
- 예측 정확도 측면에서 가장 좋은 성능을 보이는 feature subset 추출
- 기존 데이터에서 테스트를 진행할 hold-out set 별도로 구성
- 여러 번 machine learning 진행: 시간/비용 높게 발생, overfitting 높음
- 최종적으로 best feature subset 찾음: 모델의 성능을 위해서는 바람직한 방법
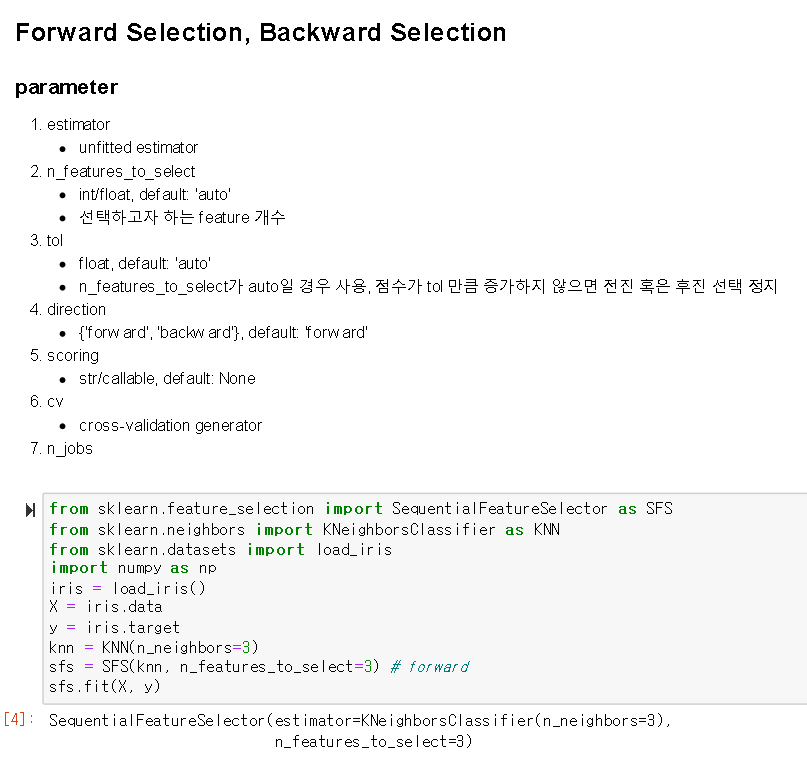
1) Forward Selection: 변수가 없는 상태로 시작하여 반복할 때마다 가장 중요한 변수를 추가하여 더 이상 성능의 향상이 없을 때까지 변수 추가
2) Backward Elimination: 모든 변수를 가지고 시작하여 가장 덜 중요한 변수를 하나씩 제거하면서 모델 성능 향상 (더 이상 성능 향상이 없을 때까지)
2) Stepwise Selection: 1번과 2번 결합한 방식, 모든 변수를 가지고 시작하여 가장 도움이 되지 않는 변수를 삭제하거나 모델에서 빠져있는 변수 중에서 가장 중요한 변수를 추가하는 방법
3. Embedded Method
- Filtering과 Wrapper의 장점을 결합한 방법
- 각각의 Feature를 직접 학습하며 모델의 정확도에 기여하는 feature 선택 (모델 자체에 feature selection 기능 추가되어 있는 경우)
- 계수가 0이 아닌 feature 선택 --> 낮은 복잡성 모델 훈련, 학습 절차 최적화
1) LASSO: L1-norm 통한 제약
2) Ridge: L2-norm을 통한 제약
3) ElasticNet: 1), 2) 선형결합
4) SelectFromModel: decision tree 기반 알고리즘에서 feature 뽑는 방법 (RandomForest 등)
sklearn을 이용한 feature selection




참고 자료
https://wooono.tistory.com/249
https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.SelectFromModel.html
728x90
반응형
'Data Science > Machine Learning' 카테고리의 다른 글
| Sampling 기법 (0) | 2023.09.11 |
|---|
